
محققان اپل توانایی مدلهای بزرگ زبانی را به چالش کشیدند

در تحولی تازه که میتواند رویکرد صنعت هوش مصنوعی به مدلهای زبانی بزرگ (LLMها) را بهشدت تحتتاثیر بگذارد، تیم تحقیقاتی اپل مقالهای منتشر کرده است که توانایی این مدلها در استدلال منطقی، حل مسئله و تعمیمپذیری خارج از الگوهای آموزشی را بهشکل قابل توجهی زیر سوال میبرد. این مقاله طبق گزارشی که وبلاگ گریمارکوس از آن منتشر کرده است، دنباله قدرتمند بر انتقادات پیشین به مدلهای مبتنی بر یادگیری عمیق است و واکنشهای گستردهای را در جامعه علمی و صنعتی به دنبال داشته است.
مقاله جدید اپل بهطور خاص روی توانایی مدلهای زبانی بزرگ در حل مسائل کلاسیک منطقی مانند «برج هانوی» تمرکز دارد؛ مسئلهای ساده ولی نمادین در علوم کامپیوتر که نیازمند استدلال مرحلهبهمرحله و پیروی از الگوریتم مشخصی است. در این مقاله نشان داده شده که حتی مدلهای پیشرفتهای مانند Claude و o3-mini، با وجود تواناییهای بالا در برخی وظایف زبانی، در حل نسخههای پیچیدهتر این مسئله (مثلا با ۷ یا ۸ دیسک) عملکرد بسیار ضعیفی دارند.
 پازل برج هانوی
پازل برج هانوی
ایمان میرزاده، محقق ایرانی حوزه یادگیری ماشینی و عمیق شرکت اپل و از پژوهشگران ارشد این تحقیقات، درمورد محدودیتهای مدلهای بزرگ زبانی در استدلال واقعی میگوید: «مساله تنها حل پازل نیست» و به نظر مدلهای زبانی حتی در دنبال کردن یک روند مشخص برای استدلال نیز به مشکل میخورند. میرزاده میگوید: «در بخش ۴.۴ این مقاله ما آزمایشی داریم که در آن الگوریتم راهحل را در اختیار مدل میگذاریم و تنها کاری که باید بکند دنبال کردن مرالح است. اما حتی این کار هم به عملکرد آن هیچ کمکی نمیکند.»
بنابراین حتی زمانی که الگوریتم حل مسئله به مدلها داده میشود و از آنها خواسته میشود فقط مراحل را دنبال کنند، عملکرد همچنان ضعیف باقی میماند. این یافته بهشدت توانایی این مدلها در استدلال منطقی و تعمیم الگوریتمیک را زیر سوال میبرد.
 بالای شکل: تنظیمات ما امکان تایید پاسخهای نهایی و ردپاهای استدلالی در میان را فراهم میکند تا تجزیهتحلیل دقیق رفتار فکری مدل امکانپذیر شود. پایین سمپ چپ و میانه: مدلهای غیراستدلالگر در پیچیدگی پایین دقت بیشتری دارند و از لحاظ توکن بهینه هستند. با افزایش پیچیدگی، مدلهای استدلالمحور عملکرد بهتری را به ثبت میرسانند اما به توکن بیشتری نیاز است تا اینکه هردوی مدلها پس از یک سرحد با شکست کامل روبرو میشوند و ردپای کوتاهتری دارند. پایین سمت راست: برای مواردی که به درستی حل شدهاند، مدل استدلالمحور Claude 3.7، پاسخها را در پیچیدگی پایین زود پیدا میکند و در پیچیدگی بالا دیرتر. در مواردی که شکست خوردهاند، این مدل معمولا روی یک پاسخ اولیه اشتباه متمرکز میشود و بودجه توکنی خود را صرف آن میکند. هردو مورد نشانگر نقصهایی در فرایند استدلال هستند.
بالای شکل: تنظیمات ما امکان تایید پاسخهای نهایی و ردپاهای استدلالی در میان را فراهم میکند تا تجزیهتحلیل دقیق رفتار فکری مدل امکانپذیر شود. پایین سمپ چپ و میانه: مدلهای غیراستدلالگر در پیچیدگی پایین دقت بیشتری دارند و از لحاظ توکن بهینه هستند. با افزایش پیچیدگی، مدلهای استدلالمحور عملکرد بهتری را به ثبت میرسانند اما به توکن بیشتری نیاز است تا اینکه هردوی مدلها پس از یک سرحد با شکست کامل روبرو میشوند و ردپای کوتاهتری دارند. پایین سمت راست: برای مواردی که به درستی حل شدهاند، مدل استدلالمحور Claude 3.7، پاسخها را در پیچیدگی پایین زود پیدا میکند و در پیچیدگی بالا دیرتر. در مواردی که شکست خوردهاند، این مدل معمولا روی یک پاسخ اولیه اشتباه متمرکز میشود و بودجه توکنی خود را صرف آن میکند. هردو مورد نشانگر نقصهایی در فرایند استدلال هستند.
این مقاله در واقع دنبالهای بر انتقادات دیرینه افرادی چون گری مارکوس و سابارائو (رائو) کامبامپاتی است. مارکوس، که از دهه ۹۰ میلادی در زمینه محدودیتهای شبکههای عصبی تحقیق کرده است، سالهاست هشدار میدهد که این مدلها تنها در محدوده دادههای آموزشی تعمیمپذیر هستند و در مواجهه با ورودیهای با شکست مواجه میشوند.
از سوی دیگر، رائو بارها نشان داده که اصطلاحاتی مانند «زنجیره تفکر (یا زنجیره استدلال)» که از آن با عنوان «Chain of Thought» در LLMها یاد میشود، بیشتر توهمبرانگیز هستند تا واقعا نشاندهنده روند منطقی یا شناختی. یکی از یافتههای او این است که خروجیهای به ظاهر منطقی LLMها اغلب با فرآیند واقعی استنتاجشان مطابقت ندارد.
مسئله برج هانوی: معیاری ساده برای یک ضعف بزرگ
در مقاله اپل، برج هانوی بهعنوان یک بنچمارک استفاده شده که اگرچه برای انسانهای باهوش و صبور، حتی در سنین پایین، قابل حل است، اما مدلهای زبانی بزرگ در مواجهه با نسخههای دشوارتر آن دچار خطای شدید میشوند.
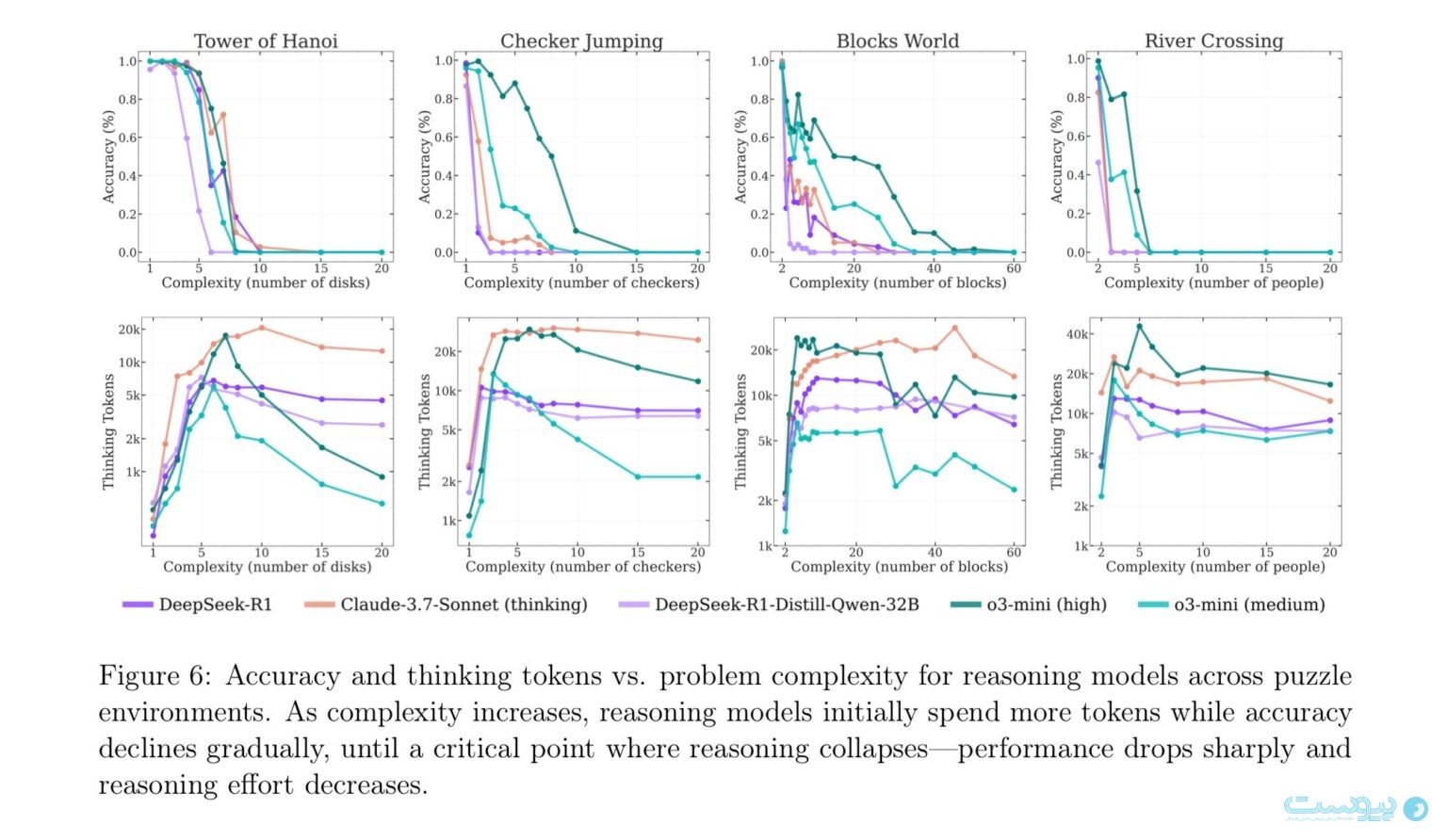 دقت و توکنهای تفکر در مقابل پیچیدگی مساله برای مدلهای استدلالمحور در محیطهای پازل. با افزایش پیچیدگی، مدلهای استدلالگر ابتدا توکنهای بیشتری را خرج می:نند در حال که دقت به تدریج کاهش پیدا میکند تا یک لحظه حیاتی که استدلال فرو میپاشد و عملکرد به سقوط میکند و تلاش استدلال کاهش مییابد.
دقت و توکنهای تفکر در مقابل پیچیدگی مساله برای مدلهای استدلالمحور در محیطهای پازل. با افزایش پیچیدگی، مدلهای استدلالگر ابتدا توکنهای بیشتری را خرج می:نند در حال که دقت به تدریج کاهش پیدا میکند تا یک لحظه حیاتی که استدلال فرو میپاشد و عملکرد به سقوط میکند و تلاش استدلال کاهش مییابد.
برای مقایسه، الگوریتم حل برج هانوی سالها پیش توسط «هرب سیمون»، یکی از بنیانگذاران واقعی هوش مصنوعی، طراحی شده بود و اکنون برای دانشجویان ترم اول رشته کامپیوتر ساده و ابتدایی محسوب میشود.
ضعف اصلی LLMها: فقدان الگوریتم درونی و حافظه پایدار
یکی از استدلالهای اصلی مقاله اپل این است که مدلهای بزرگ زبانی در درک، حفظ و اجرای الگوریتمهای مشخص، دچار نقص بنیادین هستند. در حالی که رایانهها از گذشته برای حل مسائل پیچیده و حفظ دادهها طراحی شدهاند، این مدلها علیرغم در اختیار داشتن منابع عظیم محاسباتی و حافظه، نتوانستهاند در سادهترین وظایف الگوریتمیک عملکرد باثباتی ارائه دهند.
مارکوس در واکنش به مقاله اپل تأکید میکند که هدف از توسعه AGI (هوش مصنوعی عمومی) نباید تقلید کامل از انسان باشد، بلکه باید ترکیبی از تطبیقپذیری انسانی و دقت محاسباتی ماشین باشد و این چیزی است که در حال حاضر LLMها به آن نزدیک هم نشدهاند.
آیا مقایسه با انسانها منصفانه است؟
در میان انتقادات معدود به مقاله، برخی اشاره کردهاند که حتی انسانهای عادی هم ممکن است در نسخههای پیچیدهتر برج هانوی اشتباه کنند، و بنابراین این معیار شاید بیش از حد سختگیرانه باشد. اما نویسندگان مقاله پاسخ میدهند که انتظار از AGI، صرفا تقلید از انسان نیست، بلکه ارائه عملکردی باثبات و قابل اتکا در حل مسائل مهم است.
مقاله اپل نتیجهگیری مهمی دارد: مدلهای زبانی بزرگ، با وجود قابلیتهایی در تولید متن، ترجمه، یا حتی کدنویسی اولیه، نمیتوانند جایگزینی برای الگوریتمهای دقیق و کلاسیک باشند. آنها نمیتوانند بازی شطرنج را بهتر از موتورهای سنتی انجام دهند، نمیتوانند پایگاههای داده را بهتر از سیستمهای موجود مدیریت کنند، و نمیتوانند ساختار پروتئینها را بهتر از سیستمهای نوروسمبولیک طراحی کنند.
به عبارت دیگر، LLMها ابزارهایی مفید برای برخی کاربردهای خاص همچون تولید محتوا یا کمک به نویسندگان هستند اما نباید بهعنوان مسیر اصلی برای دستیابی به AGI در نظر گرفته شوند.
در نهایت، مارکوس و رائو هر دو معتقدند که آینده موفق هوش مصنوعی ممکن است در رویکردهای ترکیبی نهفته باشد؛ یعنی مدلهایی که از قدرت یادگیری آماری LLMها بهره میبرند، ولی در کنار آن از منطق نمادین، الگوریتمهای مشخص و حافظه ساختیافته نیز استفاده میکنند.