
دریاچه داده چیست؟
امروزه انواع جدیدی از دادهها با رشد سرسامآوری در حال شکلگیری هستند. دادههایی که توسط وبسایتهای سازمانها، صفحات شبکههای اجتماعی، سنسورها و دستگاههای متصل به وب، اطلاعات مسیرهای حرکتی با دستگاههای GPS و بهطور عمومی اینترنت اشیاء و شبکههای اجتماعی یا سازوکارهای نظیر آنها ایجاد می شوند، این پرسش را به وجود آوردهاند که آیا اساساً استفاده از فناوری «انبار داده» به منظور ذخیره و تحلیل این اطلاعات از اثربخشی ِ لازم برخوردارند یا خیر.
یکی از موضوعاتی که در تحلیل انواع جدید دادهها اهمیت دارد، حجم بالایی از دادههاست که با سرعتی سرسامآور رشد میکنند و مدلهای ذخیرهسازی و تحلیلهای مبتنی بر رایانههای منفرد، پاسخگوی آنها نیستند. از طرفی توسعه پلتفرمهای مختلف ذخیرهسازی دادهها مانند فایل سیستمهای توزیعشده در دادههای بزرگ (مانند Hadoop) یا سیستمهای ذخیره سازی ابری (مانند Amazon S۳) که انواع مختلفی از دادههای ساخت یافته یا غیر ساختیافته را در خود ذخیره میکنند و لزوم تحلیل دقیق و سریع آنها، مدل انبار داده سنتی را به صورت جدی به چالش کشیده است.
مفهوم دریاچه داده (Data lake) در پاسخگویی به نیاز مذکور به تدریج توسعه پیدا کرده است. به منظور تشریح این مفهوم از تمثیلی استفاده میکنیم که جیمز دیکسون (James Dixon) مدیر ارشد فناوری پنتاهو (Pentaho) برای اولین بار به کار برد. اگر انبار داده را مشابه یک بطری آب تصفیهشده، بستهبندی شده و آماده مصرف در نظر بگیریم دریاچه داده (همانند نام آن) دریاچهای است که آب از منابع مختلف ( آب باران، چشمه ها، رودها یا منابع دیگر) در آن سرازیر شده و افراد میتوانند از آب دریاچه برای شنا، آشامیدن یا حتی نمونهبرداری! استفاده کنند. در صورتیکه بخواهیم تفاوتهای رویکرد دریاچه داده و انبار داده در تحلیل دادهها را بیان کنیم، میتوانیم به موارد زیر به عنوان تفاوتهای اساسی اشاره کنیم:
دادهها کاملاً در دریاچه داده قرار میگیرند و از هیچ دادهای صرفنظر نمیشود. این رویکرد برخلاف رویکرد انبار داده در ذخیرهسازی و پالایش دادهها است که در آن تنها اطلاعاتی در انبار داده قرار میگیرد که بتواند در تحلیلها مورد استفاده قرار گیرد.
دادههای پایینترین سطوح (مثلاً توضیحات یک فرد در یک مقاله یا یک وبسایت) بدون تغییر یا با حداقل تغییرات به دریاچه داده منتقل میشوند که این مهم، برخلاف رویکرد انبار داده است که تبدیل و تغییر (Transformation) یکی از پیشفرضهای اساسی و اولیه ورود اطلاعات به آن محسوب میشود. در مثال قبل ممکن است برای ذخیرهسازی توضیحات یک فرد در یک مقاله یا وبسایت با مدل انبار داده تنها به استخراج کلید واژهها از توضیحات و ذخیرهسازی آن در یک جدول بانک اطلاعاتی بسنده کرد.
در دریاچه داده توضیحات فرد، نحوه پیمایش یک سایت توسط کاربر و اطلاعات سنسورهایی که توسط دستگاهها تولید شده است، بدون توجه به منبع و ساختار ذخیره میشوند. این رویکرد ذخیرهسازی دادهها که در آن داده، بدون توجه به ساختار و منبع ذخیره میشود را اصطلاحاً «خواندن با ساختار» (Schema On Read) نامیده میشود. این رویکردی متفاوت از ذخیرهسازی دادهها در انبار داده است که در آن، ابتدا ساختاری که دادهها باید در آن قرار گیرد طراحی میشود و سپس داده ها در ساختار قرار میگیرند که به آن نوشتن با ساختار (Schema On Write) گفته میشود.
در بیشتر سازمانها، نزدیک به ۸۰% از استفادهکنندگان از اطلاعات، استفادهکنندگان عملیاتی محسوب میشوند. نیاز این دسته از کاربران این است که گزارشها و شاخصهای مورد نیاز خود را مشاهده کنند. این موارد معمولاً دارای ساختاری از پیش تعریفشده هستند و رویکرد انبار داده به دلیل ساختیافته بودن اطلاعات، برای این دسته از کاربران قابل درک و استفاده است.
معمولا ۱۰% از کاربران یک سازمان نیاز به تجزیه و تحلیل عمیق دادهها پیدا میکنند. این دسته از کاربران میتوانند از انبار داده برای تجزیه و تحلیلهای مورد نیاز خود استفاده کنند اما گاهی اوقات، نیاز به دسترسی به منبع اصلی داده مورد نیاز است و کاربران ناچارند به دادهها در سیستمهای تولیدکننده آن مراجعه کنند. درصد کمی از کاربران سازمانها نیازمند تحلیلهای عمیق و پیچیده بر روی دادهها هستند.
دانشمندان و تحلیلگران داده (Data Scientists) جزو این دسته از کاربران قرار میگیرند. این گروه از کاربران، از انواع دادههای ساختیافته یا ساختنیافته و ابزارهای تجزیه و تحلیل پیشرفته بر روی دادهها مانند دادهکاوی، متنکاوی، تحلیل آماری، مدلهای پیشبینیکننده، تحلیل جریان پیمایش یک سایت و روشهای مشابهاستفاده میکنند. با توجه به اینکه در فرآیند تحلیلهای پیشرفته، تحلیلگر از قبل، درباره اینکه چه ویژگیها یا دادههایی موردنیاز هستند و از کدامیک باید صرفنظر شود آگاه نیست، رویکرد خواندن با ساختار (Schema On Read) و عدم حذف یا تبدیل اطلاعات بهتر میتواند به نیاز تحلیلیِ این دسته از کاربران پاسخ دهد. جالب است بدانید با استفاده از رویکرد دریاچه داده میتوان به نیازهای هر سه دسته از این کاربران به شکل مناسبی پاسخ داد.
تفاوت دیگر دو رویکرد در نحوه مواجهه با تغییر است. در رویکرد انبار داده باید با توجه به تحلیلهای مورد نیاز، ساختارهای مرتبط در انبار داده طراحی شده باشد تا امکان ذخیرهسازی اطلاعات در ساختار مربوطه فراهم شود و پس از آن، فرایند تکمیل اطلاعات در انبار داده (شامل خواندن، تبدیل و بارگذاری) آن را برای تحلیل در اختیار استفادهکننده قرار میدهد. با توجه به اینکه این فرایند معمولاً طولانی است، در سالهای اخیر مفهوم Self Service BI و در اختیار قرار دادن امکاناتی که کاربران خود بتوانند راساً فعالیت یکپارچهسازی و تحلیل اطلاعات را به انجام برسانند، مورد توجه قرار گرفتهاند و بعضی از ابزارهای تجاری موجود در بازار نیز به این سمت حرکت کردهاند.
اما در رویکرد دریاچه داده، دادهها به صورت خام در فرمتهای اولیه نگهداری میشوند و ابزارهایی در اختیار کاربران قرار داده میشود که بتوانند دادهها را با همین شکل موردارزیابی و تحلیل قرار دهند. گاهی اوقات این ارزیابیها مشخص میکنند که چه بخشی از دادهها، از ارزش لازم برای تحلیلهای کاملتر برخوردارند و در ادامه ممکن است برای این بخش از دادهها، ساختار مورد نیاز را طراحی کنند (انبار داده). در غیر اینصورت از هدر رفتن زمان زیادی از تیم تحلیل داده به منظور ساخت انبار داده بر روی دادههایی که واجد ارزش نیستند جلوگیری شود.
کاربرانی که دادهها را از طریق دریاچه داده مورد استفاده قرار میدهند، به اطلاعات خام دسترسی دارند و از آنجا که هیچیک از فرایندهای پرهزینه و زمانبر تبدیل، پاکسازی و ساختاردهی روی دادهها انجام نمیشود، میتوان سریعتر و کمهزینهتر فعالیت تحلیل دادهها را آغاز کرد. اما باید به این نکته توجه داشت که این روش برای کاربران تحلیلگر کسبوکار قابل پیادهسازی نیست و این دسته از کاربران که بیشتر با گزارش و شاخص سروکار دارند، نیاز دارند که دادهها در یک فرایند منسجم تبدیل، پاکسازی و ساختاردهی شده و در قالب گزارشها و شاخصها در اختیارشان قرار گیرد. در حقیقت، در دریاچه داده، هزینههای پاکسازی و ساختاردهی به دادهها کاهش می یابد، با این وجود هزینههای تحلیل دادهها افزایش یافته و بر پیچیدگی تحلیل داده افزوده میشود.
با توجه به توضیحات بالا، خوب است نگاهی به طرحواره معماری پیاده سازی دریاچه داده داشته باشیم.
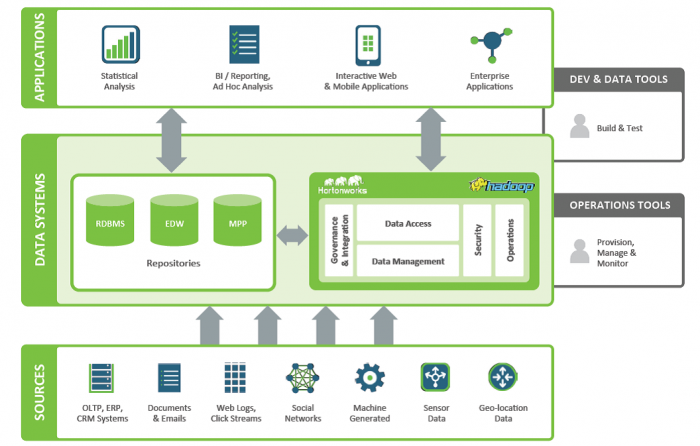
در طرح معماری بالا در پایینترین سطح، منابع داده شامل سیستمهای تولیدکننده داده قرار دارند. دادههای تمامی این منابع، در لایه میانی (سیستم دادهای سازمان) قرار داده میشوند. سیستم دادهای شامل بانکهای اطلاعاتی رابطهای، انبارهای داده، و اجزای سیستم مدیریت داده (برای نمونه مبتنی بر Hadoop) است. در لایه برنامههای کاربردی، سیستمهای اطلاعاتی سازمانی، سیستمهای تحلیلگر اطلاعات و سایر سیستمهای استفادهکننده از داده قرار دارند. شاید تنها نکتهی مبهم در این طرح، بخش سیستم مدیریت داده مبتنی بر Hadoop باشد که با نگاهی دقیقتر به جزییات این سیستم و اجزای آن درک بهتری از مفهوم دریاچه داده و نحوه برخورد با چالشهای ذخیرهسازی و تحلیل آن به دست خواهیم آورد.

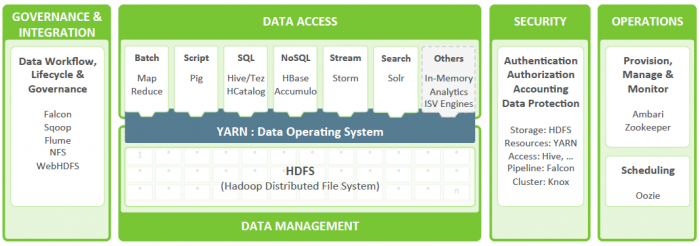
نمودار بالا اجزای کلی این سیستم را نمایش می دهد. در نمودار بعدی به جزئیات ابزارها و فناوریهایی اشاره شده است که در هر یک از بخشهای اشاره شده در طرح بالا مورد استفاده قرار میگیرد. این ابزارها و فناوریها در مقالات بعدی به شکل دقیقتری توصیف خواهند شد.
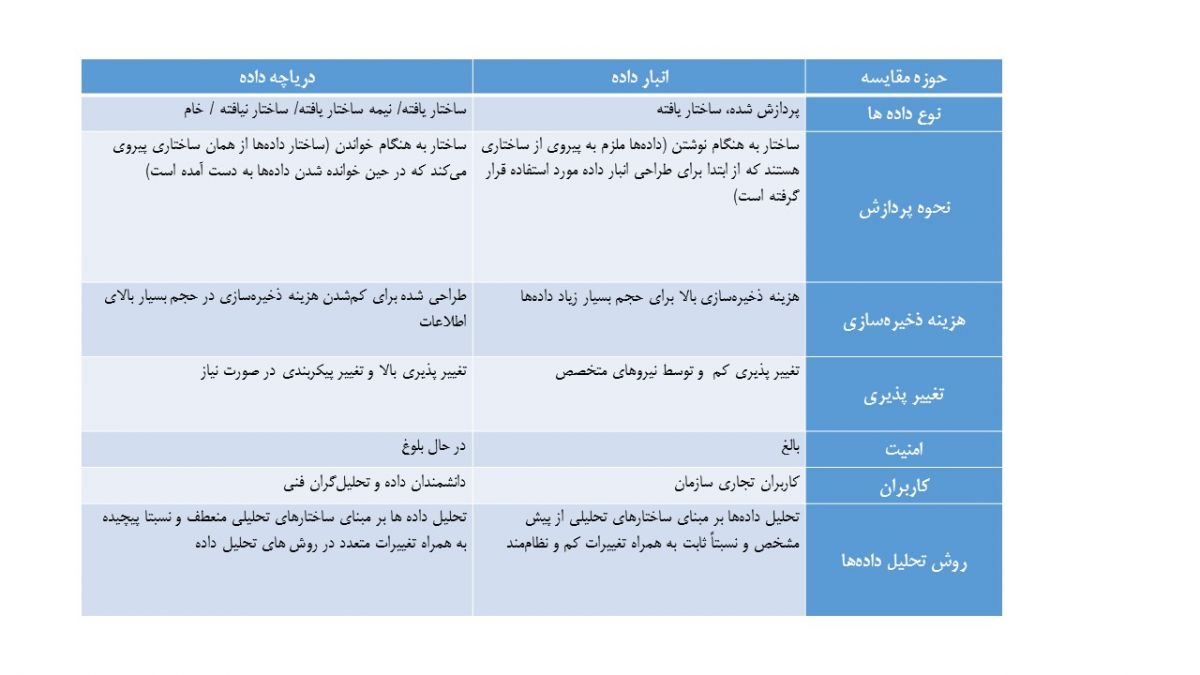
تفاوت دو رویکرد انبار داده و دریاچه داده در تحلیل اطلاعات را میتوان در جدول زیر خلاصه کرد:
نتیجهگیری
موضوعات مربوط به دادهها و تحلیل آنها در راستای ارتقاء عملکرد سازمان بسیار مورد توجه واقع شدهاند. با اضافه شدن ابعادی مانند حجم بالای دادهها، تنوع و سرعت افزایش آنها و مطرح شدن تحلیلهای پیشرفته بر مبنای بزرگ داده (BIG Data Analytics) رویکردهای جدید تجزیه و تحلیل دادهها، ابزارها و فناوریهای جدیدی را به وجود آوردند. استفاده مناسب از هر یک از این فناوریها نیازمند توجه به رویکردهایی است که هر کدام از این مفاهیم بر مبنای آن شکل گرفتهاند. به موازات این موضوع، انطباق مناسب این رویکردها با نیازمندیهای سازمان میتواند موجب انتخاب فناوریهایی شود که به شکلی بهینه، نیازهای تحلیلی سازمان را مرتفع میسازند. دانستن رویکردهای انبار داده یا دریاچه داده در موضوع تحلیل دادهها میتواند به مدیران ارشد اطلاعاتی سازمانها در انتخاب مدل مناسب برای حل این موضوع و تحلیل دقیقتر داده ها کمک کند.